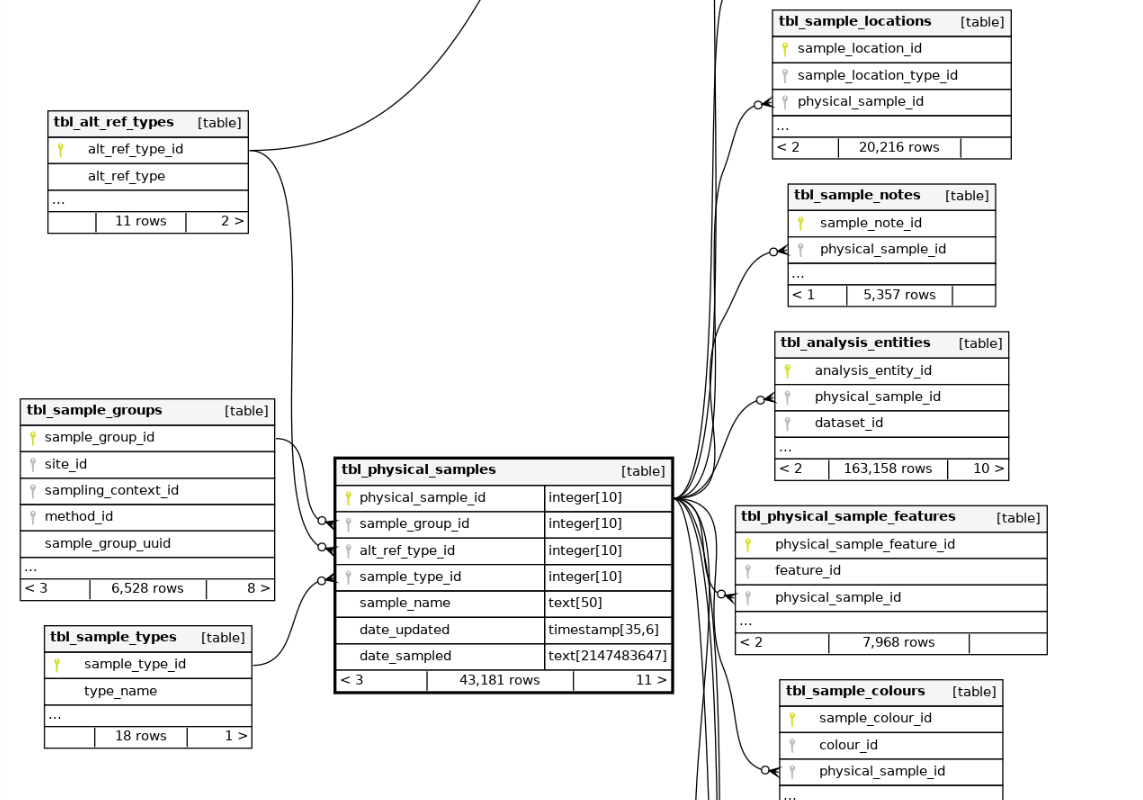
This join assigns each sample number to a sample group of one item.
(SEAD is set up to deal with proxy information from data sets from a single excavation. Proxies are often small items like insects and pollen. Therefore, the level of “sample_group” was set up for things like a single scoop of soil, which is later investigated to count the number of grains of pollen, or number of insects, etc. As a result, in SEAD it is the sample_group that is tied to a specific site, and all physical samples are associated with a sample group. For studies like this one, that draw from many different sites, with a focus on dates obtained from one particular species of bones, no information remains in the dataset to determine if the bones had once been part of a sample group when they were collected Therefore it is easiest to simply assign a unique sample_group_id to each sample).