Element refers to the types of things that were analysed for the dataset.
In this dataset the radiocarbon analyses were performed on bones, and this column specifies which type of bones were analysed (e.g. Femur, Mandibula, Humerus, etc.).
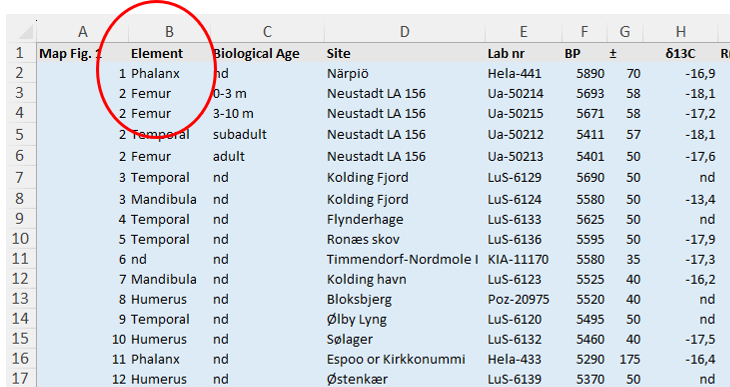
This corresponds to element_name,
which gives an abbreviated name for the element, such as ‘mni’, ‘seed’, or ‘leaf’, and is part of the table tbl_abundance_elements.
abundance elements
- create and fill in a sheet called abundance_elements in the radiocarbon_Glykou_etal_2021_input.xlsx spreadsheet spreadsheet with the following columns
- system_id This column is filled incrementally, starting with 1 and is used during the import process to keep track of the data in this sheet, and to cross-reference its connections to the other sheets.
- abundance_element_id This will be the unique ide associated with each element_name, as these are all new element_names in SEAD, they need to be assigned a number in the system
- record_type_id as these analyses were all performed on animal bones, use record_type_id =14, which is the value already in SEAD for animal bones.
- element_name This is where each unique value from this column will be entered. As this will be the first SEAD dataset to report analyses of bones, all of these are new element names:
- Cranium
- Femur
- Fibula
- Humerus
- Mandibula
- nd
- Occipitale
- Phalanx
- Radius
- Scapula
- Temporal
- Vertebra
- element_description As these are all new element types for SEAD, ask the researcher to provide a description to go with each of these element names which will help non-specialists understand what each term means
abundances
we must also record the actual abundance and information relating to each element in the dataset
- create and fill in a sheet called abundances in the radiocarbon_Glykou_etal_2021_input.xlsx spreadsheet spreadsheet with the following columns
- system_id This column is filled incrementally, starting with 1 and is used during the import process to keep track of the data in this sheet, and to cross-reference its connections to the other sheets.
- taxon_id This specifies the taxonomic unit related to this record, where taxon_id = 1 = sp., and is the value assumed for this data set when the initial mapping was done.
- analysis_entity_id copy this information from the system_id numbers of the tbl_analysis_entities sheet of this spreadsheet (see below)
- abundance_element_id copy this information from the system_id numbers of the above mentioned abundance_elements sheet. (If it helps to keep track of which ones have been done, you can also add a column to show the corresponding element_name on this sheet, but it is not needed for the import process, this column is enough to connect the information for the relational part of the database.)
analysis entities
Each element has experienced one or more types of analysis that led to the dataset which we need to define
- create and fill in a sheet called tbl_analysis_entities in the radiocarbon_Glykou_etal_2021_input.xlsx spreadsheet spreadsheet with the following columns
- system_id This column is filled incrementally, starting with 1 and is used during the import process to keep track of the data in this sheet, and to cross-reference its connections to the other sheets.
finish filling in this page from here
- physical_sample_id copy this information from the system_id numbers of the physical samples sheet (see the note for E. Lab nr). (If it helps to keep track of which ones have been done, you can also add a column to show the corresponding sample_name on this sheet, but it is not needed for the import process, this column is enough to connect the information for the relational part of the database.)
- dataset_id copy this information from the system_id numbers of the datasets sheet (see the note for 0. Datset).
- analysis_entity_id
- [[abundance]]